Practices for real world data science
As I write this introduction, I have been working as a data scientist for Electricity Maps for about 8 months. Overall, I am responsible, together with the other data scientist in the team, for delivering high data quality at the end of the entire data processing pipeline. That data can be real-time, historical or forecasted.
In a nutshell, the generation of Electricity Maps’ data is a multi-stage process. Firstly, varied data points from numerous public data sources about electricity are aggregated. Secondly, they are validated and standardised against a reference schema. Finally, they are run through our flow-tracing algorithm for the generation of worldwide real-time hourly electricity consumption figures; and their associated greenhouse gas emissions.
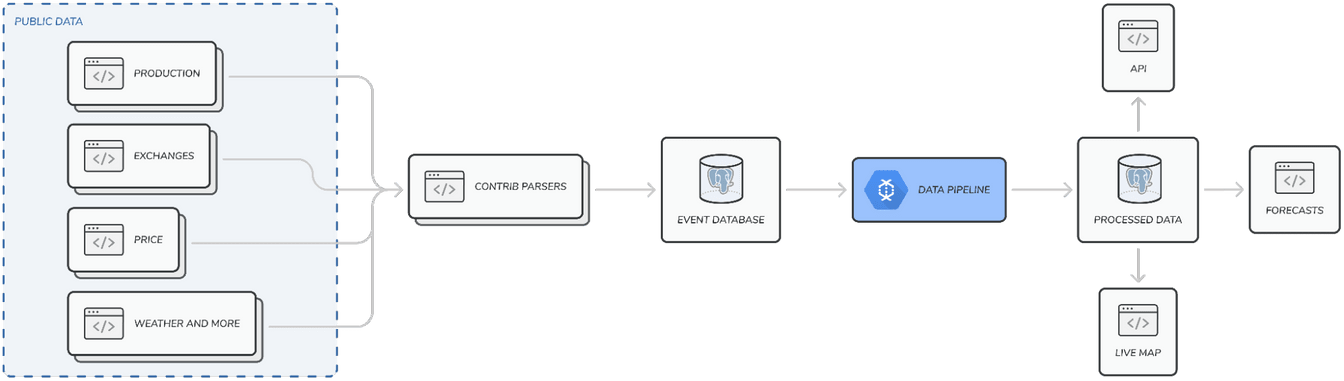
This data is at the core of our mission: to organise the world’s electricity data to drive the transition towards a truly decarbonised electricity system. This global ambition has two important consequences. We must first be able to overcome data sources becoming erroneous or unavailable at any moment. Secondly, we must come up with clever ways to generate truthful data for regions of the world where reliable public electrical data sources are unavailable.
These consequences reveal my other current responsibilities; develop and maintain a wide range of models to capture the dynamics of electrical production per factor and exchanges in vastly different areas of the world, and have enough domain expertise to ensure that they behave according to what is physically possible.

These responsibilities are far-reaching and evolve rapidly as Electricity Maps scales up. It is impossible to be highly specialised when only 11 (10 brights + me) people are fighting for something that is way too big for them only. The good news is that as Electricity Maps grows, I am constantly able to redefine my role as a data scientist, and the practices I should adopt to help the team be successful.
Recently, we opened a position to find a brilliant mind that can become the most knowledgeable about our data quality. At the same time, I started delivering on tasks whose scope overflowed into the realm of data engineering. The former event, because it will most likely reduce the scope of my responsibilities, pushed me to redefine what I, as a data scientist, should focus my efforts on. The latter, because it is much more common within software/data engineering, revealed to me the necessity of defining and implementing good practices for successfully delivering on that newly defined scope.
Hence this blog post, which aims at capturing my current thoughts around the data scientist role and practices that should be more widely adopted within the profession. This opinion piece is a reflection of the prism through which I perceive my work. It is therefore highly influenced by my work for Electricity Maps, my previous interrogations between research and industry, and my relative freshness within this position. For that reason, it might get updated occasionally.
Table of content:
The data scientist role
Data scientists are often described as part mathematician, part computer scientist and part trend-spotter\(^1\) by corporates that don’t understand that finding someone that can be a stellar mathematician, computer scientist and analyst at once might be extremely hard. I would tend to think that a company that looks for all three competencies in a single individual has an immature data infrastructure and lacks the experience to realise that asking a single individual to do it all might be counterproductive.
This thought pattern has probably been harmful to many recent graduates who have been developing and researching state-of-the-art machine learning and optimisation models during their studies to end up having to spend most of their time researching data sources, and frying their brains over complex software architecture problems.
The previous description could correspond to three different jobs; the expertise in computer science could be delegated to a data engineer, the expertise in analysis delegated to a data analyst, while the mathematics and modelling should be the realm of data scientists.
This means that in most cases, recruiting a data scientist should be preceded by hiring a data engineer, who will be much better suited for building up the infrastructure that will support the forthcoming modelling efforts. With libraries like scikit-learn or PyTorch, any talented data engineer would already be able to build up a decent pipeline for predictions or estimations without a deep understanding of the models themselves.
With the infrastructure already built up, a data scientist can then generate tremendous value, by capturing and accumulating marginal gains from guiding the creation of automated Q&A systems, ensuring consistency between data distributions (distributional shifts are common with real-world dynamic data), and researching and putting in production new models\(^2\).
Meanwhile, the visualisations generated, trends identified and domain expertise accumulated by a data analyst through its constant interaction with the end data can increase the engagement with and actionability of the data, and generate customer-side insights. This will help improve the overall quality of the generated data, and make sure that it fits the business requirements.
In the end, it is the compound efforts of a unified data team that should produce the data visualisations, insights generation and domain knowledge required for any given task.
Within this understanding of the data scientist role, and its strong ties to the other data positions, I tend to define the objectives of the data scientist as:
-
Ensuring consistency of data fed through the pipeline. Their knowledge of statistics and understanding of distributions makes them suited for defining rules to check the consistency of the data flowing through the pipeline. These verifications are of paramount importance before feeding data through any model. Data that does not respect the expected properties can have disastrous consequences on any model’s output. Typically, data distributions can drift and display a significant shift when compared to the data a model has been trained on, or some inputs might be periodically unavailable, affecting the computability of key features for the models.
-
Setting up a modular modelisation infrastructure with individual components that automate repetitive tasks, training, validation, monitoring etc. Ideally, this infrastructure should also offer the bindings that make the experimentation with new models seamless. For example, as is conceptualised in PyTorch Lightning, creating an independent module for data loading, and a trainer instance accelerates the setup time of any new model.
-
Researching (and implementing) new models. One needs to deserve the scientist part of his title, and any data scientist should leverage his modelling expertise to unlock varied benefits from different model classes. Furthermore, the field of machine learning has been receiving a lot of attention (no pun intended) these last years, leading to fast developments and paradigm changes (think transformers for example). The consequence is that the expertise a data scientist has over a certain class of models can quickly become outdated, and the time spent keeping up with new models will be rewarded in terms of increased model performance later on.
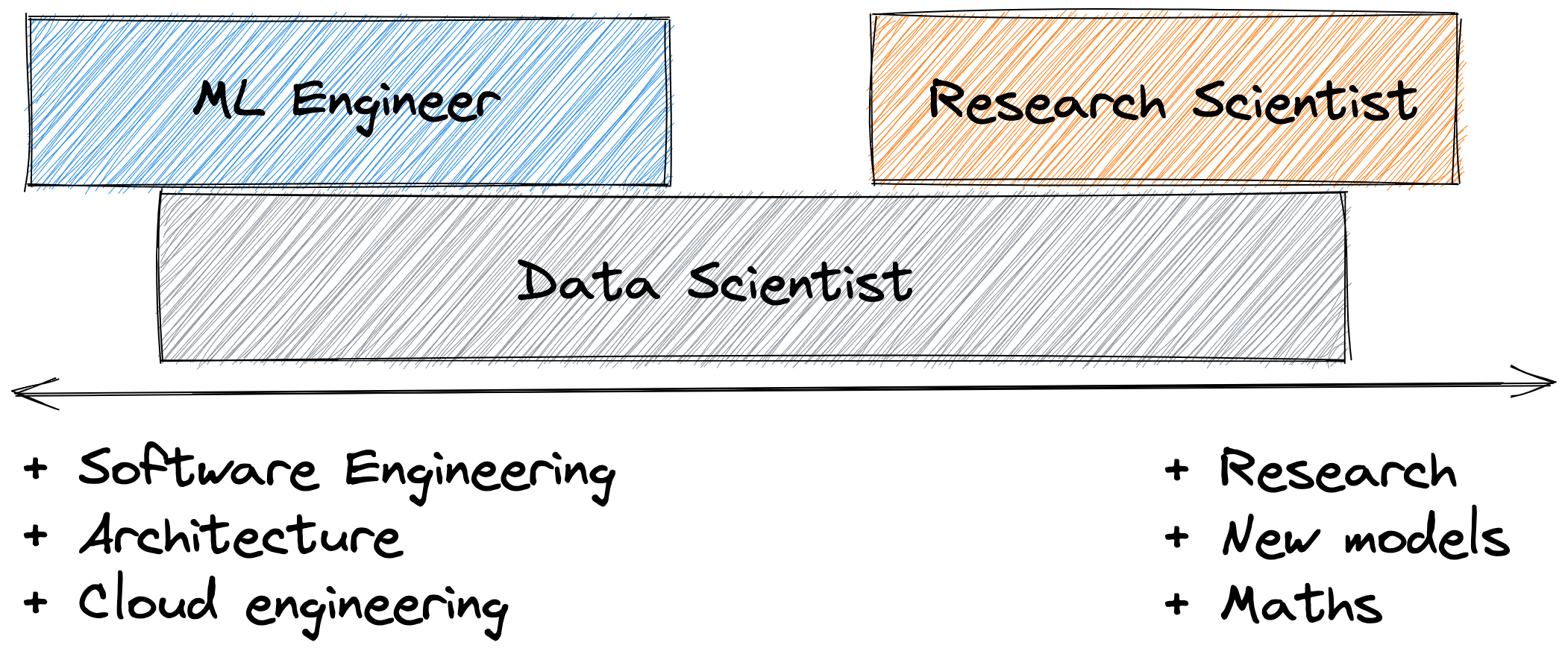
In much larger organisations, these different responsibilities might be too large for one person alone. In this case, the data scientist role can be further split up into machine learning engineers, who will inherit the practical implementation of models within the data pipeline, and research scientist, who can focus only on the modelling and research aspects.
Better understanding one’s responsibilities is essential to prioritise work efficiently, but it does not help in actually delivering on the work that has been prioritised. Learning a lot from my colleagues, I’ve come to realise that the adoption of simple principles does.
Practices
Define the scope of your work
There is an inherent risk within data science related to the hybrid position it occupies between machine learning research and commercial applications. As a data scientist, one can naturally tend to perfect a model’s performance, tweaking hyperparameters, fine-tuning pre-processing steps, and running multiple experiments with incremental improvements, as we’ve been taught throughout school or in a research environment. The problem with that process is how time and resource intensive it can be - Tracking the results of multiple experiments at once is arguably one of the most strenuous tasks in machine learning, and providing time estimates for when quantitative improvements can be secured is seldom more accurate than the output of a random number generator -, while the business requirements for a model might not require such a high performance model. I would therefore strongly advise in favour of making requirements clear before starting to research and implement any model.
The requirements should cover expected accuracy, robustness, scalability and model freshness.

Invest in tooling
Tooling is crucial as it defines how easy it will be to take a model from an experimentation phase to a production-ready application. The way machine learning is commonly taught, with an emphasis on creating one-off notebooks or scripts that do not need to take into consideration dependencies and inter-operability, does not translate well to real-world problems tackled by cross-functional teams. Having proper tooling shared by all in the team is essential, yet mostly invisible, to allow fast iterations and adoption of models performing better.
On the opposite, the absence of proper tooling can easily lead to a mountain of technical debt where the combined efforts of poor code quality, naming conventions and architecture will seriously undermine the maintainability, testability and scalability of any model. (Just look at any graduate student’s thesis code for a good example, especially the data_processing_final_v2.py file)

At the very basis of this effort are the adoption of common code style (think automatic linting with black & isort in python for example) and versioning systems (besides e.g GitHub, investing in a functional versioning system for datasets and metadata might be worthwhile).
Next, the adoption of internal tools that facilitate the development of any new project has far-reaching benefits for aligning the different team members’ output, making reviewing each other’s code far easier and freeing up thinking space to focus on the actual deliverable. These can include for example creating a collection of libraries that each offers a specific set of services (e.g DB access, configuration, plotting style etc), creating domain-related toolboxes, or even setting up a well documented templating system.
Finally, using the tools already set up should simplify the separation of concerns for the various essential parts of the data science workflow. Time invested into converting each of these steps (data fetching, data preparation, features generation, training, validation, evaluation, serving etc) into their own independent module should be rewarded pretty quickly in terms of adaptability, testability and scalability of the system.
Test first, then debug
In software engineering, it is very common practice to test every piece of production-ready code. From unit testing, to end-to-end testing, frameworks for reliably testing individual logic and their global cooperation ensure that the produced software (mostly) behaves as expected. In data science, whether due to the sometimes non-deterministic nature of the models used, the additional burden of testing the data itself, or to the hubris of the data scientist (that’s what you get when a job gets so much hype), testing is not as strictly mandated. The consequence is that important parts of the modelling infrastructure can get adopted in production without full test coverage. This directly affects the reliability and hence the trustworthiness of the models’ output.
I don’t want here to expand precisely on how to test data science systems in practice, as it would extend beyond the scope of this post, and also because good resources already exist out there\(^3\). Instead, I want to provide two simple, but sticky rules. Firstly, as often as possible when debugging, write first a test that isolates and replicates the bug under investigation. This has multiple benefits; speeding up the investigation by focusing it, providing a direct way to verify that the fix indeed fixes the bug without introducing any regression somewhere else, and expanding test coverage without much effort! Secondly, always test the data itself. Machine learning systems have an additional dependency on the data compared to standard software systems, and the testing setup must account for it.
Conclusion
I hope that you found this post instructive. As hinted earlier, I mostly wrote up this post to help me structure my thoughts around the development of my role working for Electricity Maps, but I would be thrilled to hear your opinion on the definition of the data scientist role and what principles he/she should adopt to successfully get his new ideas and models implemented in the real-world. I’m only beginning my journey and still have a lot to learn from the community ✌️.
Thanks for reading!
2: Some might argue that putting models in production, because it is mostly an engineering task, should be delegated to someone else that has a stronger emphasis on software engineering. In the line of what Eugene Yan defends in his Unpopular opinion - Data scientists should be more end-to-end, I tend to think that letting data scientists own the entire process from getting data to delivering value based on identified patterns result in faster execution and output that is more in line with the context and the business requirements.
3: See for example the extensive tutorial from MadeWithML